In this blog post I present my findings of an independent analytical and computational study of using genetic algorithms to train neural networks. This was my final project for an Introduction to Cognitive Science course that I took at The University of Texas at Austin, under Dr. David Beaver.
My motivation comes from the fact that animal brains, and particularly the human brain which is the topic of this entire course, are themselves genetically evolved neural networks. Therefore, artificial neural networks trained by genetic algorithms are a good starting rudimentary model of understanding the hardware of the brain. This sentiment is echoed in my primary reference,
Evolutionary Algorithms for Neural Network Design and Training, Branke et al (1995). However, the paper mostly discusses the idea qualitatively, and I decided that since it is a relatively simple algorithm to implement, I would benefit my understanding to a much greater extent by implementing it myself on some simple networks.
Background
McCulloch-Pitt Neurons

A McCulloch-Pitt neuron is a simple decision-making unit that forms the building block for the kind of artificial neural networks I have constructed and studied. It has a set of inputs (each of which is a 0/1 bit) connected to it via weighted links. It checks if the weighted sum of the inputs exceeds a specified threshold

, and passes an output 1 if it does, and 0 if not.
Artificial neural networks
Neurons of the above kind can be connected and their weights and thresholds set in ways to have their action emulate desired computational operations. This is called an artificial neural network. The following are two simple networks that act as 2-input OR and AND gates:
Each network has weights of 1 each. The OR gate has a threshold of 0.5 whereas the AND gate has a threshold of 1.5.
It should already become clear that there isn’t a unique set of weights and thresholds to have a neural network perform a certain task. We shall delve more on this later.
Training artificial neural networks
What if we wish our network to perform a certain kind of operation but we do not know what weights and thresholds will do the work? First, we need to define in a simple way what is meant by a certain operation. It means mapping the set of possible input tuples to their right answers. This is called a truth table. The following is the truth table for a two-input XOR gate for example:
A standard way of converging on the right set of weights for a neural network prescribed to perform a certain task is by the use of learning rules. These rules update the weights based on the difference between the correct answer for a set of inputs and the actual answer.
Limitations of learning-rule based weight training
However, this simple method often fails to converge because the number of nodes in the network and the connections between them may be wrong to start with, such that no set of weights between them would provide the desired operation. We can see this when we use the simple connectivity of the OR and AND gates illustrated above and try to emulate a XOR gate and the process does not converge.
Therefore, in a more general case the problem might be extended to include the structure of the network as well, and now the question extends to finding:
- The number of nodes in the network.
- Their connectivity, i.e. the adjacency matrix (the
 th element of this is 0 or 1 depending on whether the
th element of this is 0 or 1 depending on whether the 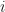 th and
th and  th nodes are connected).
th nodes are connected).
- The weights of the connections. 2 and 3 may be combined into finding a weighted adjacency matrix, where a zero matrix element implies that two nodes are disconnected, and a non-zero element specifies the weight of the connection.
- The thresholds of firing of the neurons.
Some of these variables are discrete and others are continuous, and they are interrelated in a complex way. All of this means that learning rules cannot be simply generalized to find all the variables using an updating scheme. Herein lies the utility of genetic algorithms.
Genetic Algorithms
Genetic algorithms are commonly used where the problem can be formulated as a search in several dimensional parameter space, and a fitness function can be attached to any choice of parameters (a measure that mirrors how close the solution represented by those parameters is to the desired solution). The following schematic illustrates a typical genetic algorithm.
In the context of constructing a neural network, genetic algorithms provide a natural method of solution in the general case where all of the mentioned variables are floating and can be concatenated into a string.
Implementation
There are some important points to note about my particular implementation of the method:
- For the sake of simplicity and owing to limited time, the only floating variables were the weights and thresholds, i.e. the number and connectivity of neurons was fixed. It is not hard to imagine extending this implementation to float those parameters as well.
- The fitness function is chosen to be the sum of the absolute differences between the correct answers and the answers given by the network. For example, consider the situation when we are trying to model an OR gate and our network gives us the following answers:
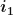 |
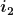 |
Actual answer |
Network’s answer |
| 0 |
0 |
0 |
1 |
| 0 |
1 |
1 |
0 |
| 1 |
0 |
1 |
0 |
| 1 |
1 |
1 |
1 |
Then the fitness of the network is going to be  . By this definition, then, the lower the fitness, the better the network, and a fitness of zero means that the network achieves the desired behaviour for all inputs. As long as the fitness measure ranks the individuals accurately based on their performance, the exact form of the fitness is irrelevant to the working of the algorithm.
. By this definition, then, the lower the fitness, the better the network, and a fitness of zero means that the network achieves the desired behaviour for all inputs. As long as the fitness measure ranks the individuals accurately based on their performance, the exact form of the fitness is irrelevant to the working of the algorithm.
- The reproduction is sexless, i.e. there is no mating. This means that in each iteration, the fittest individual is selected and a new generation is created by mutating each of its parameters.
- To speed up convergence and make it monotonic, if in an iteration all of the offspring are less fit than the parent, the parent is selected again. This ensures there is no retrograde evolution.
Code
The following is the program in R:
xornet<-function(i1,i2,w){
m1=i1*w[1]+i2*w[3]>w[7]
m2=i1*w[2]+i2*w[4]>w[8]
return(m1*w[5]+m2*w[6]>w[9])
}
#calculates the fitness of a network defined by a set of parameters
fitness<-function(w){
s=0
for (i1 in c(0,1)){
for (i2 in c(0,1)){
s=s+abs(xornet(i1,i2,w)-xor(i1,i2))
}
}
return(s)
}
#initialize random population of weight vectors
pop<-NULL
for (i in 1:10)
{
pop<-rbind(pop, rnorm(9))
}
ftraj<-NULL
wspace<-NULL
for (gen in 1:1000){
#sort according to fitness
fitnesslist<-NULL
for (i in 1:dim(pop)[1]){
fitnesslist<-c(fitnesslist, fitness(pop[i,]))
}
pop<-cbind(pop,fitnesslist)
pop<-pop[order(pop[,10]),]
#list the parameter vectors that work. Can be plotted to visualize the solution region in parameter space
for (i in 1:10){
if ((pop[,10]==0)[i]){
wspace<-rbind(wspace,c(pop[i,1],pop[i,2]))
}
}
#list highest fitness against generations
ftraj<-rbind(ftraj,fitness(pop[1,]))
#generate new generation by mutations from fittest
fittest=pop[1,]
pop<-NULL
for (i in 1:9){
pop<-cbind(pop, rnorm(10, mean = fittest[i], sd = 1))
}
pop<-rbind(fittest[1:9],pop)
}
plot(ftraj, pch=19, xlab="Generation", ylab="Fitness of the fittest")
lines(ftraj)
This code is implementing a neural network for a XOR gate, which corresponds to the highlighted lines. Those are the lines that have to be changed accordingly for other networks.
2-input OR Gate
Analytical observations

In order for the above network to reproduce the truth table of an OR gate, we must have the following:
- For (0,0):
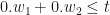 , i.e.
, i.e.  .
.
- For (1,0):
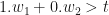 , i.e.
, i.e.  .
.
- Similarly for (0,1), we have
 .
.
- For (1,1):
 , i.e.
, i.e. 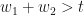 , which is automatically satisfied as long as 2 and 3 are satisfied.
, which is automatically satisfied as long as 2 and 3 are satisfied.
Thus, in the parameter space there is a region of solutions, not a unique set of weights and threshold. These solutions occupy the unbounded region defined by criteria 1, 2 and 3. The surfaces of such regions are called decision boundaries of the perceptrons (neural networks).
In my simplified implementation I further specified the threshold to 1 (as can be seen in the definition of the ornet function in the code), so that the search space of parameters reduces to the 2D  space and the solution region is defined by the area
space and the solution region is defined by the area 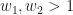 , illustrated below:
, illustrated below:

Results
One may consider the evolution of the parameter vector to be a Markov chain. If we plot the fittest of each generation, the Markov chain looks like this for an example run:
Notice how we start outside the solution region and wander into it.
If we plot the fitness of the fittest individual of each generation for the markov chain, it converges to 0. Here is a plot for an example run:
This is a scatter plot of values after convergence for a sample run:

This is in accordance with the solution region schematically depicted previously.
2-input AND gate
Analytical observations
Following similar arguments as for the OR gate, we can conclude the following about the weights and thresholds if the network is supposed to work as an AND gate instead:
- For (0,0): ,i.e. .
- For (1,0):
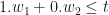 , i.e.
, i.e.  .
.
- Similarly for (0,1), we have
 .
.
- For (1,1): , i.e. , which is no longer automatically satisfied.
For a fixed threshold (say 1), the solutions in the parameter space now occupy a bounded triangular region:
Results
All the results are analogous to the case of the OR gate. The only plot I will show here is the space of solutions for an example run, which is in accordance with the solution region found analytically above:
2-input XOR gate
Analytical observations
In an assignment we saw how a network connectivity like the one I’ve used so far fails to converge to the operation for a XOR gate for any choice of weights. This is unsurprising because the response of a XOR gate is not a linear function of its inputs. This requires the network to be more complex. In particular, here is a network constructed by observation that functions as a XOR gate:
The intermediate OR gate ensures that at least one of the inputs is on, while the NOT AND gate ensures that both are not on at the same time. The outputs from these pass through a final AND gate that makes sure that both these conditions are met.
Results
As we can see, there is some variability introduced in the weights as well as the thresholds. This is an opportunity to use the power of the genetic algorithm to easily extend the method to include the thresholds as floating parameters as well, which is what I have done with the code. The number of nodes and the connectivity is still fixed.
The parameter space is now 9-dimensional, and the solution region occupies a much tinier fraction of it. Therefore convergence takes longer. Here is a plot of the convergence of fitness for a sample run:
The Markov chain or the solution parameter vectors cannot themselves be plotted because it is a 9-dimensional space.
The weight and threshold values that resulted from this run have been plugged into the schematic. As we can see, the logic of this network is quite different from the one constructed before by observation, yet it manages to produce the same truth table as a XOR gate. This is because the structure, nature, connectivity and operation of the hidden units of two networks may be different, yet their overall behaviour may be the same.
The emergence of such alternate solutions allows one to see the problem anew in retrospect. This is indeed the beauty of genetic algorithms. It is an unguided method for obtaining seemingly designed solutions.
Conclusions
As we saw, we can use genetic algorithms to train artificial neural networks to perform desired computations. The advantages of the algorithm over standard learning-rule based updating are several.
- It is more general, i.e. it can be used to find out the number of nodes, connectivity and firing thresholds as well, and is therefore easily scalable for large and complex networks.
- It is an entirely unguided method and requires little design and foresight.
- As a side-effect, it also provides a way to visualize the solution region in the search space by plotting solution vectors starting from different starting conditions.
A disadvantage is that since it is unguided by conscious design, it is often much slower to converge than learning-rule based updating schemes.

















Pingback: Cracking Random Number Generators using Machine Learning – Part 1: xorshift128 – NCC Group Research
First, thank you for this very informative post!
I’m struggling a bit to understand the XOR calculation here, however.
If we take your first XOR example (“a network constructed by observation that functions as a XOR gate”) and assume input 1 = 0 and input 2 = 1, here’s what I calculated:
Hidden neuron 1 = (01) + (11) + 0.5 = 1.5
Hidden neuron 2 = (0-1) + (1-1) – 1.5 = -2.5
Output = (1.51) + (-2.51) + 1.5 = 0.5
Now, repeating this same thing for the other 3 possible input combos (1/0, 0/0, 1/1), we get the following outputs respectively:
1/0: 0.5
0/0: 0.5
1/1: 0.5
All the outputs are the same, no?
LikeLike
Apologies, looks like WordPress converted my multiplication symbols into italics. So Reposting using x for multiplication:
First, thank you for this very informative post!
I’m struggling a bit to understand the XOR calculation here, however.
If we take your first XOR example (“a network constructed by observation that functions as a XOR gate”) and assume input 1 = 0 and input 2 = 1, here’s what I calculated:
Hidden neuron 1 = (0 x 1) + (1 x 1) + 0.5 = 1.5
Hidden neuron 2 = (0 x -1) + (1 x -1) – 1.5 = -2.5
Output = (1.5 x 1) + (-2.5 x 1) + 1.5 = 0.5
Now, repeating this same thing for the other 3 possible input combos (1/0, 0/0, 1/1), we get the following outputs respectively:
1/0: 0.5
0/0: 0.5
1/1: 0.5
All the outputs are the same, no?
LikeLike
Hi Jaypinho, just seeing your comment after several months now (I don’t check my blog so much any more, but my email is abhranil@abhranil.net).
In your calculations, you are summing the weighted inputs of a neuron, then adding the value that I have written inside the neuron. That value is the value of the threshold, it’s not to be added to the total input. You just take the total input and compare to the threshold value. If it’s more than the threshold, the neuron outputs 1, otherwise 0. If you do this, I think the XOR gate works.
LikeLike